
稼働中の ElastiCache Redis にサービスの更新(engine-update)の通知があったので手動で適用をしました。メンテナンスのヘルプ - Amazon ElastiCache | AWS によると数秒のダウンタイムが発生するとのことですが、どのくらいサービスがダウンするのか redis-cli を使って調べてみたので記録を残します。
目次
- ElastiCache Redis の環境
- 検証用の環境
- サービス更新の様子
- 1 台目の書き込みコマンドのエラー停止
- 2 台目の書き込みコマンドはエラーなし
- 1 台目の読み込みコマンドのエラー停止
- 更新終了
- まとめ
- 参考サイト
ElastiCache Redis の環境
- モード:Redis
- ノードのタイプ:cache.t3.micro
- エンジンのバージョン 互換性:6.2.6
- シャード:1
- ノードの数:2
- マルチ AZ:enabled
- 自動フェイルオーバー:enabled
- データ量:約 50 MB
- 更新のタイプ:security-update
検証用の環境
- Amazon ECS-optimized Amazon Linux 2 × 2 台
- Docker 20.10.17
- redis:6.2.6-alpine Docker イメージ
1 台目
ターミナルウィンドウを 2 個立ち上げ、それぞれのウィンドウで 1 台目の Amazon Linux にログインし Docker コンテナにログインします。
docker run --rm -it redis:6.2.6-alpine ash読み書きのコマンドを実行して、更新中にエラーが出るかどうかを確認します。
ウィンドウ 1 では、1 秒に 1 回、数字を 1 ずつ増やしながら書き込み。
redis-cli -h redis-primary-endpoint set mykey1 "1"
redis-cli -h redis-primary-endpoint -i 1 -r 3600 incr mykey1ウィンドウ 2 では、1 秒に 1 回、上記で書き込んだキーを読み取り。
redis-cli -h redis-primary-endpoint -i 1 -r 3600 get mykey12 台目
ターミナルウィンドウを追加で 2 個立ち上げ、2 台目の Amazon Linux でコンテナにログインします。それぞれのウィンドウで以下のコマンドを実行します。
ウィンドウ 3 では、ループしながら 1 秒に 1 回、数字を 1 ずつ増やしながら別のキーに書き込み。date コマンドで日時も表示します。
for i in $(seq 1 3600); do
date
redis-cli -h redis-primary-endpoint set mykey2 ${i}
sleep 1
doneウィンドウ 4 では、ループしながら 1 秒に 1 回、上記のキーを読み取り。
while [ true ]; do
date
redis-cli -h redis-primary-endpoint get mykey2
sleep 1
doneサービス更新の様子
サービス更新をする前に前述の 4 個のスクリプトを流しておきます。
サービス更新を開始すると、ステータスが Waiting-to-start になります。
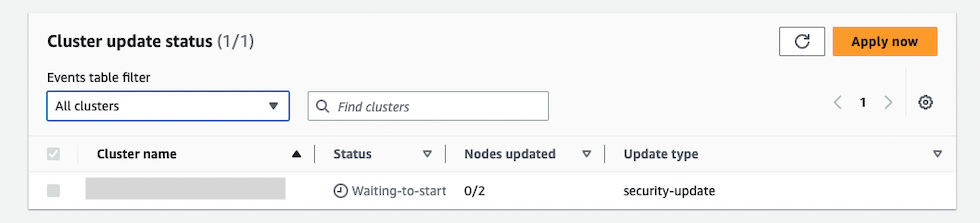
しばらくして、ステータスが In-progress になりました。
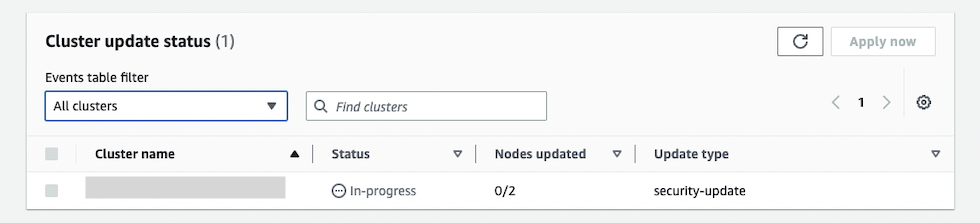
数分後、ノードのうち 1 台の更新が終わり、ステータスが Waiting-to-start になりました。
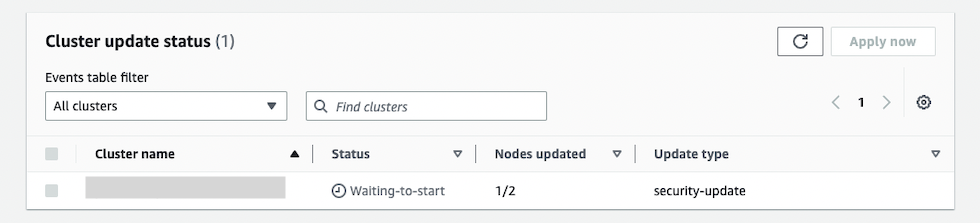
さらに数分後、ステータスが In-progress になりました。
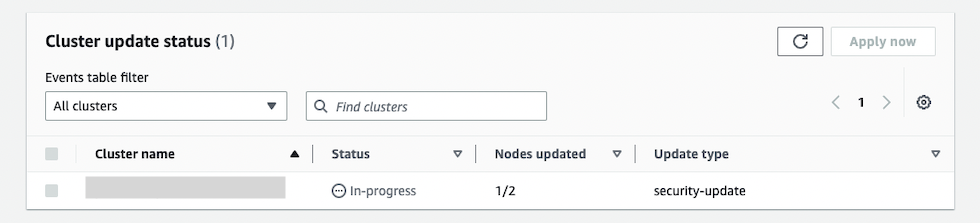
1 台目の書き込みコマンドのエラー停止
この後、1 台目のターミナルウィンドウに変化が。書き込みをしているコマンドがエラーで止まりました。エラーメッセージから、プライマリだったインスタンスがレプリカに切り替わり、書き込みに失敗したようです。コネクションがクローズされたというエラーも出ていました。
/data # redis-cli -h redis-primary-endpoint -i 1 -r 3600 incr mykey1
(integer) 1
(integer) 2
...
(integer) 1083
(integer) 1084
(integer) 1085
(error) READONLY You can't write against a read only replica.
Error: Server closed the connection
/data # 書き込みのコマンドを再実行。
(integer) 1084
(integer) 1085
/data # redis-cli -h redis-primary-endpoint -i 1 -r 3600 incr mykey1
(integer) 1086
(integer) 1087読み込みコマンドは特にエラーがでなかったのですが、書き込みを再開してもしばらく同じ数字が出力され続け、その後、数字が飛んだ状態で出力が再開されました。
"1085"
"1085"
"1085"
"1085"
"1105"
"1108"
"1109"
"1110"
"1111"
"1112"
"1113"
"1114"2 台目の書き込みコマンドはエラーなし
2 台目の検証マシンで流していた書き込みコマンドはエラーを検出できませんでした。ダウンタイムが 1 秒より短かった可能性があります。
for i in $(seq 1 3600); do
date
redis-cli -h redis-primary-endpoint set mykey2 ${i}
sleep 1
done
Tue Apr 16 05:13:19 UTC 2023
OK
Tue Apr 16 05:13:20 UTC 2023
OK
Tue Apr 16 05:13:21 UTC 2023
OK
Tue Apr 16 05:13:22 UTC 2023
OK
Tue Apr 16 05:13:23 UTC 2023
OK
Tue Apr 16 05:13:24 UTC 2023
OK
Tue Apr 16 05:13:25 UTC 2023
OK
Tue Apr 16 05:13:26 UTC 2023
OK
Tue Apr 16 05:13:27 UTC 2023
OKwhile [ true ]; do
date
redis-cli -h redis-primary-endpoint get mykey2
sleep 1
done
Tue Apr 16 05:13:19 UTC 2023
"1085"
Tue Apr 16 05:13:20 UTC 2023
"1086"
Tue Apr 16 05:13:21 UTC 2023
"1087"
Tue Apr 16 05:13:22 UTC 2023
"1088"
Tue Apr 16 05:13:23 UTC 2023
"1089"
Tue Apr 16 05:13:24 UTC 2023
"1090"
Tue Apr 16 05:13:25 UTC 2023
"1091"
Tue Apr 16 05:13:26 UTC 2023
"1092"
Tue Apr 16 05:13:27 UTC 20231 台目の読み込みコマンドのエラー停止
その後数分して、1 台目の読み込みコマンドがエラーで終了しました。書き込みのコマンドには変化がありませんでした。
"1541"
"1542"
Error: Server closed the connection
/data #読み込みコマンドの再実行
"1541"
"1542"
Error: Server closed the connection
redis-cli -h redis-primary-endpoint -i 1 -r 3600 get mykey1
"1549"
"1550"更新終了
その後は特にエラーになることもなく「ステータスを更新」が complete になり、更新が完了しました。
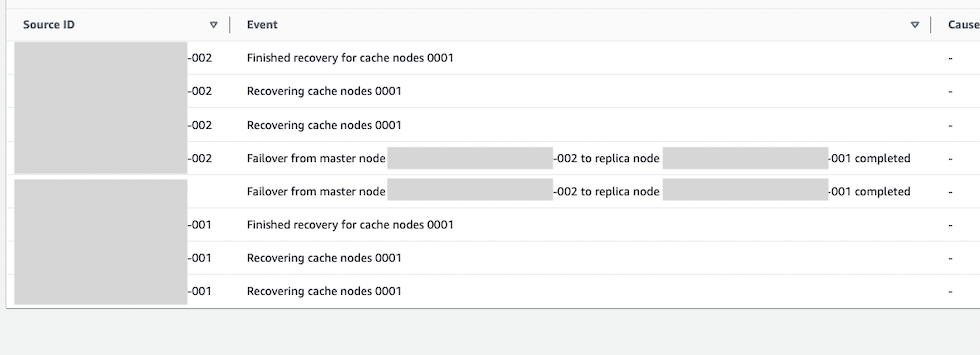
イベントを見ると、フェイルオーバーが発生していたことが分かります。先にレプリカ(末尾 001)を更新して、フェイルオーバーを発生させてレプリカ(末尾 001)をプライマリに昇格させていたと見られます。
まとめ
- redis-cli で
incrコマンドを 1 秒ごとに実行している環境では、コネクションが確立した状態を維持してコマンドが実行されていたようで、フェイルオーバーと見られるタイミングでエラーが発生した - redis-cli で、ループを回して、1 秒ごとに毎回コネクションを張っている環境では、エラーは確認ができなかった
- メンテナンスのヘルプ - Amazon ElastiCache | AWS ではダウンタイムは数秒と記載あり
- Redis のバージョンや更新のタイプ(security-update, engine-update)によってもダウンタイムは異なりそう
今回の計測ではフェイルオーバーが 1 秒以内に完了したと見られ、明確なダウンタイムの確認はできませんでした。ドキュメントにはダウンタイムは数秒と記載されているので、アプリケーション側では、エラーが起きても問題がない作りにしておく必要がありそうです。